7 Intelligent Document Processing Benefits for Your Business

Need a custom demo?
Use your own workflow and see where DocKnow can reduce manual work.
Get your demoKey Takeaways
- Intelligent document processing (IDP) uses AI, NLP, and machine learning to extract, validate, and route data from documents automatically, going far beyond what basic OCR or RPA can do.
- For diagnostic and clinical labs, the biggest IDP benefit is catching intake errors before they become denied claims and lost revenue. Onymos DocKnow is purpose-built for this.
- For financial services, insurance, and logistics teams, IDP delivers measurable ROI through faster cycle times, lower error rates, and automated compliance tracking.
- Organizations that implement IDP report an average ROI of 200-300% within the first year, with processing times cut by up to around 50%.
Is your billing team chasing down a missing patient insurance number again? Are your intake staff re-keying data that came in on a faxed requisition form? Somewhere in that backlog, a claim deadline could also be quietly expiring.
The core benefits of intelligent document processing go beyond digitizing paperwork. They’re about stopping revenue loss, compliance risk, and operational drag at the source: the document itself.
IDP uses AI to read, understand, validate, and route data from any document, structured or not, before it ever touches a downstream system. This guide breaks down the most impactful benefits, which industries gain the most, and what to look for when choosing a platform.
What Is Intelligent Document Processing?
Intelligent document processing is the use of AI (specifically NLP, machine learning, and computer vision) to automatically capture, classify, extract, and validate data from documents, regardless of format or structure.
Unlike basic OCR (which reads text) or RPA (which follows rigid rules), IDP understands context, reconciles data across sources, and learns over time. The result is clean, validated data routed directly into your downstream systems without manual re-entry.
7 Core Benefits of Intelligent Document Processing (IDP)
Most IDP benefits coverage undersells the real value, stating “it saves time” but the downstream effects of cleaner data are what truly matter: fewer denied claims, lower compliance exposure, faster decisions, and revenue that doesn’t leak out through intake errors.
Here’s where the actual impact shows up.
1. Errors Get Caught Before They Cost You Money
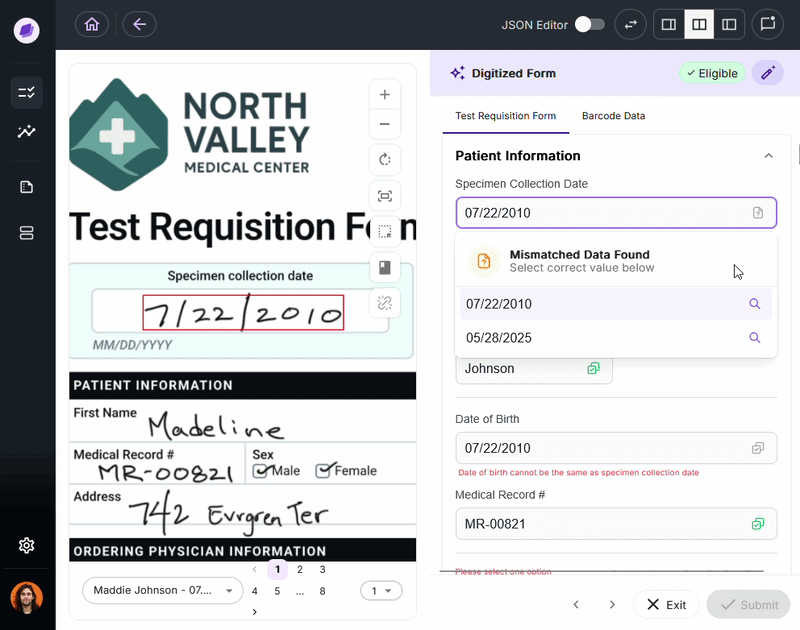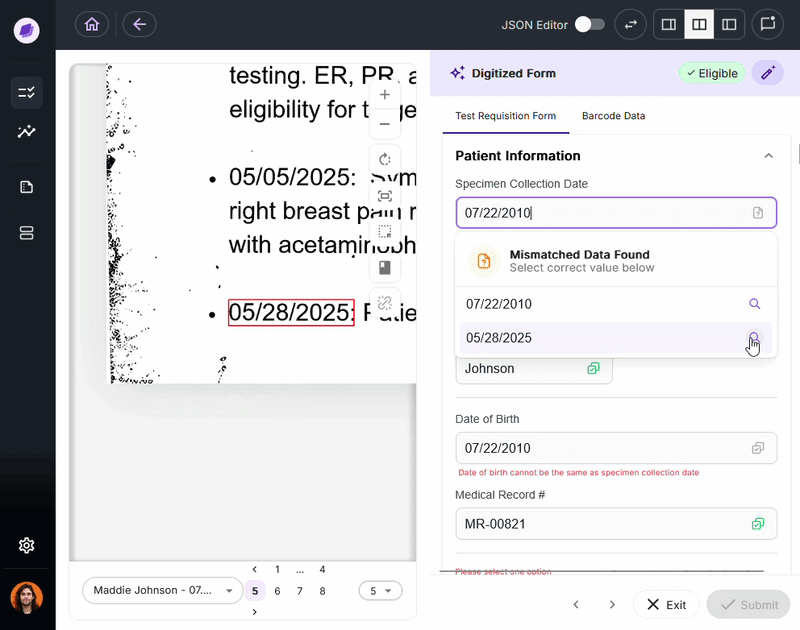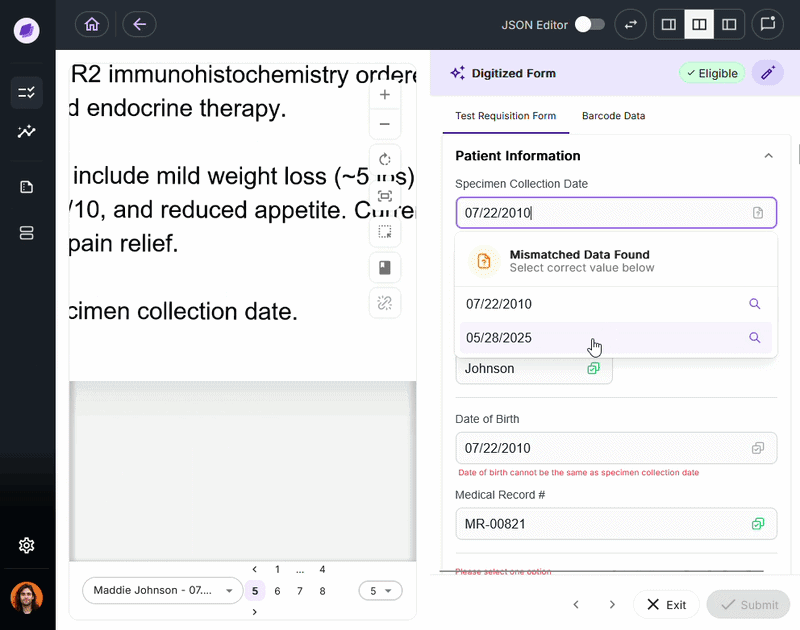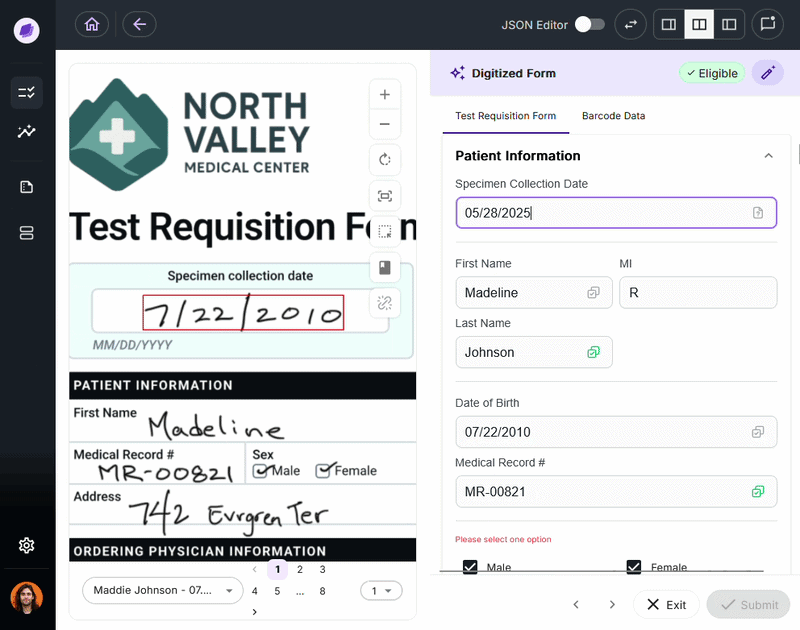
The most expensive document errors are the ones that make it through intake and surface 90 days later as a denied claim or failed audit.
IDP validates extracted data against connected systems at the point of capture. If a patient name on a test requisition form says “Charlie” but the medical record says “Charles,” a system like Onymos’s SmartSync flags that mismatch before it reaches billing.
For diagnostic labs, where a single denied claim can represent hundreds or thousands of dollars, this upstream error prevention is the core financial case for IDP.
2. Manual Data Entry Gets Eliminated, Not Just Reduced
The standard pitch for document automation is “reduce manual entry.” The honest version is: IDP can eliminate it entirely for high-volume, repetitive document types.
Lab technicians and billing teams re-keying data from test requisition forms aren’t just slow. They can also introduce a 4% average error rate per document. At 250,000 specimens per year, that’s potentially 10,000 data errors annually entering your systems.
IDP systems automatically extract, validate, and format fields using custom business rules built around your lab’s specific workflows. Every field is captured, cross-referenced, and cleaned before it reaches your LIMS or RCM system.
3. Compliance Becomes Automatic, Not a Manual Project
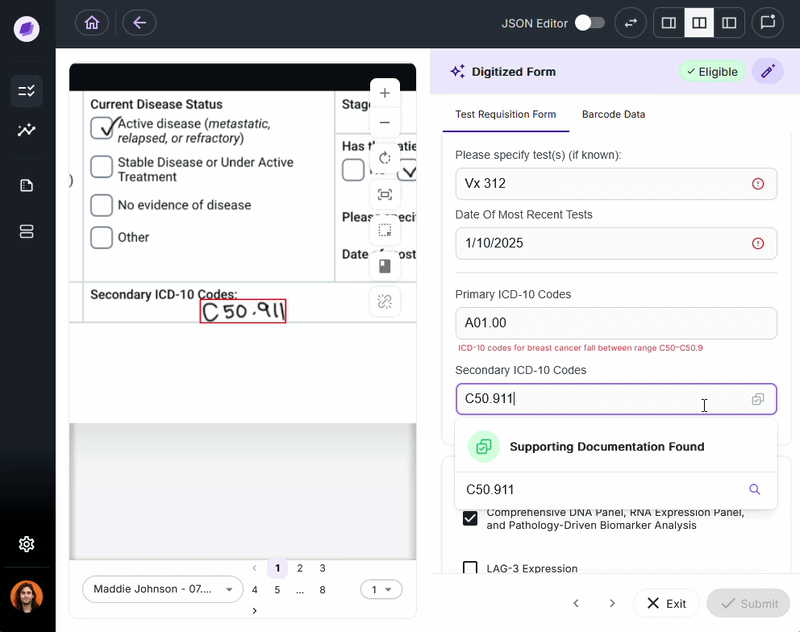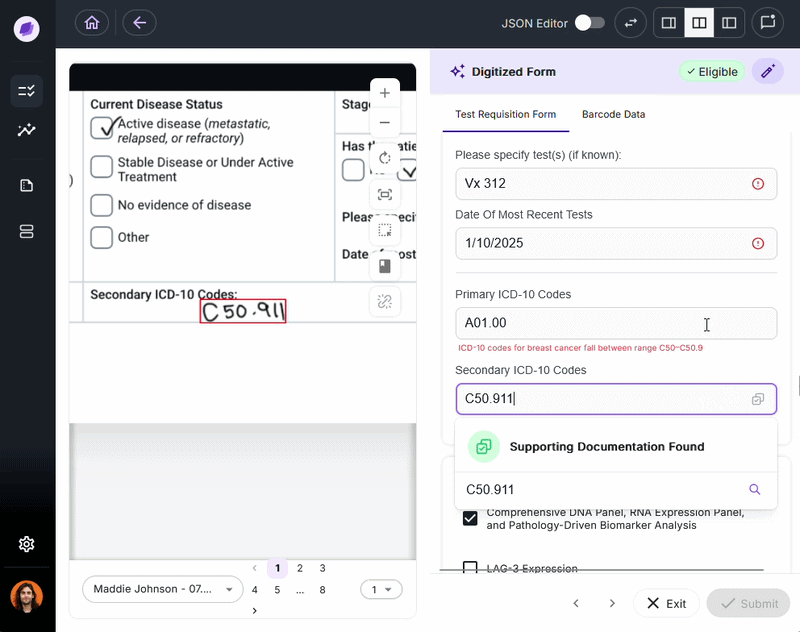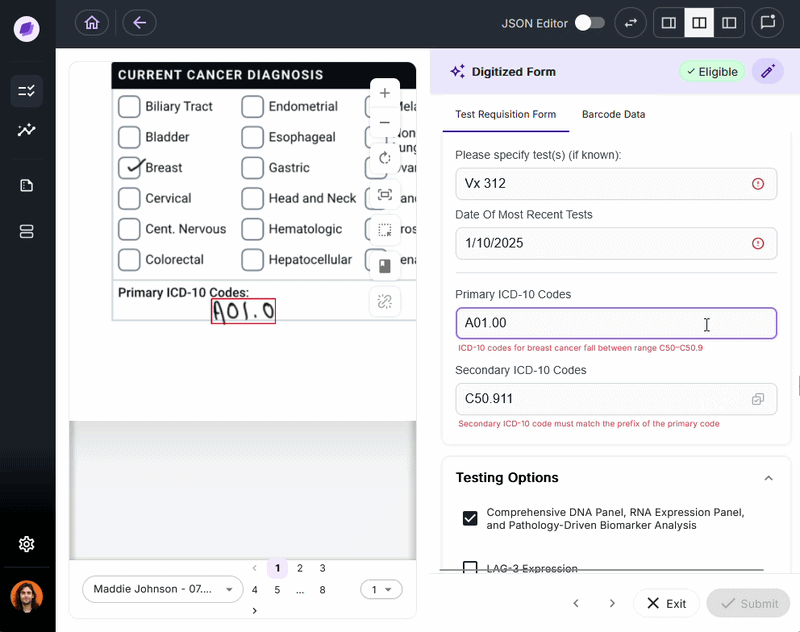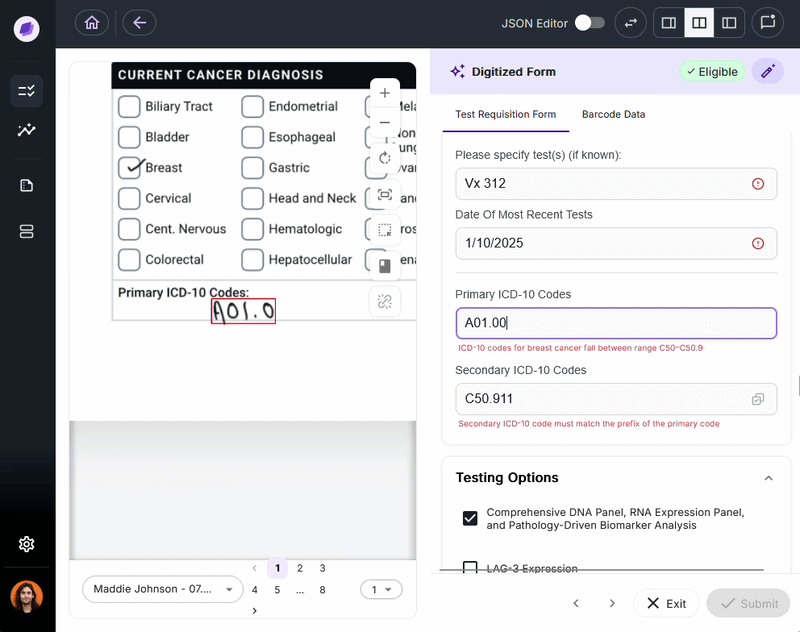
In healthcare and life sciences, compliance isn’t optional. The audit trail is the proof. The problem with manual workflows is that compliance depends entirely on people following procedures consistently. That’s not a reliable system.
IDP platforms log every document interaction at the field level: what was extracted, what was changed, who reviewed it, and when. This is a requirement for CAP and CLIA-regulated labs.
HIPAA-compliant document management built on IDP means your audit readiness isn’t something you have to prepare for manually. It becomes something that’s continuously maintained by the system itself.
4. Insurance Eligibility Gets Verified Before the Work Is Done
One of the most operationally damaging problems in lab billing is running eligibility checks after a test has been completed. If coverage fails, the lab absorbs the cost, often hundreds or thousands of dollars per test.
IDP-enabled eligibility verification runs before any work is done on the specimen. The moment intake documents arrive, the system cross-checks patient insurance details against current payer data. Problems are surfaced immediately, while there’s still time to resolve them.
This is one of the highest-ROI benefits of intelligent document processing for labs specifically: it converts a reactive, post-denial recovery workflow into a proactive upstream check that protects revenue from the start.
5. Document Volume Scales Without Headcount
Growing from 250,000 to 350,000 specimens per year doesn’t mean your billing and intake teams can grow proportionally. Manual workflows have a ceiling, and the cost of exceeding it shows up in missed deadlines, processing backlogs, and claims that expire before they’re submitted.
IDP removes the staffing bottleneck from document-intensive workflows. Because extraction, validation, and routing are automated, throughput scales with document volume rather than with headcount.
This is why labautomation software built on IDP is increasingly positioned as infrastructure rather than tooling. It makes growth operationally viable.
6. Unstructured Data Becomes Usable Data

Between 80% and 90% of all business data is unstructured, meaning it lives in PDFs, scanned forms, emails, and images that traditional systems can’t read. For labs, this includes test requisition forms, insurance cards, faxed orders, and supporting clinical documentation in dozens of formats.
IDP turns that unstructured data into structured, queryable, routable information. Not only does this unlock the data for downstream systems. It also enables analytics, reporting, and insight generation that wasn’t possible when the data was locked in documents.
Lab workflow software that integrates with IDP can surface operational patterns, flag recurring data quality issues, and support the kind of decision-making that used to require a separate data team.
7. Faster Reimbursement Cycles
Every day a claim sits in a queue waiting for missing data is a day revenue isn’t collected. For labs processing high volumes of tests with complex payer requirements, billing cycle speed is directly tied to cash flow.
For labs managing denial backlogs, IDP also supports the appeals process, automatically pulling relevant documentation, cross-referencing denial reasons, and supporting appeal letter generation without requiring manual case-by-case review.
Industries That Benefit Most from Intelligent Document Processing
IDP isn’t high-value everywhere. The ROI is highest in environments where document volume is large, document types are varied, and compliance requirements are strict.
Wherever those three factors converge, IDP stops being a complementary function and becomes critical operational infrastructure.
Clinical and Diagnostic Laboratories
Labs are arguably one of the clearest IDP use cases across all industries. Every specimen arrives with paperwork. Every one of those documents needs to be read, validated, and routed before work begins.
The specific document workflows IDP transforms in labs include: accessioning and intake, insurance eligibility pre-verification, RCM document capture (EOBs, superbills, claims), and appeal letter generation for denied claims. Mistakes in these workflows can directly delay or eliminate reimbursement.
Onymos DocKnow is currently the only IDP platform built specifically for clinical laboratory intake workflows, with native support for test requisition forms, SmartSync data reconciliation, and No-Data Architecture that keeps all patient data inside the customer’s own infrastructure.
Financial Services and Banking
Banking and insurance account for roughly 34% and 14% respectively of all IDP spending, and for good reason: loan applications, KYC onboarding documents, claims forms, and compliance filings are all document-intensive processes with high error costs.
For accounts payable, automated invoice processing has cut late payment penalties by 25%.
The compliance benefit is particularly significant: every document interaction is logged automatically, supporting audit readiness across regulatory frameworks.
Healthcare (Beyond the Lab)
Hospitals and health systems deal with patient records, consent forms, prior authorizations, and billing documentation at massive scale.
IDP connects those document workflows to EHR systems, billing platforms, and compliance systems, reducing manual handoffs and improving data fidelity across the patient journey.
IDP is becoming essential for meeting insurer documentation requirements without adding administrative staff, especially for organizations managing prior authorization workflows.
Logistics and Supply Chain
Customs documentation, bills of lading, shipping manifests, and supplier invoices are all document types with tight deadlines and high error costs.
Over 70% of logistics companies are adopting document processing automation specifically to streamline customs paperwork and shipment tracking.
IDP in logistics reduces customs clearance delays, improves invoice accuracy, and enables faster supplier payment cycles, all without proportionally increasing back-office headcount.
Common Challenges Intelligent Document Processing IDP Solves
If any of the following sound familiar, IDP is likely the right solution.
These are the operational pain points that persist when document workflows depend on manual processing.
“Our intake data is always incomplete”

You receive a test requisition form or a purchase order and something is missing, maybe a patient ID, a physician signature, a diagnostic code. Your team then spends time chasing down the information by phone, fax, or email. Meanwhile, the clock on your claim deadline is running.
IDP resolves this by validating required fields at the point of capture. Missing data is flagged immediately, before the document moves downstream. The team sees the gap while it’s still fast and cheap to fix, not 90 days later when the claim has already been denied.
For labs, this is the difference between a billing team that’s reactive (processing corrections) and one that’s proactive (preventing errors).
DocKnow’s intake automation is built around exactly this intervention point.
“We can’t scale without hiring more people”
Document volume grows faster than teams can hire for it. When you’re processing thousands of TRFs per week manually, every growth milestone creates a staffing problem. Hiring solves it temporarily…until the next volume spike.
IDP breaks that dependency. Because extraction, classification, and routing are automated, document throughput scales with the system rather than with headcount. Labs scaling up specimen volumes can maintain processing timelines and data quality without building a proportionally larger operations team.
The best LIMS software increasingly integrates with IDP for exactly this reason: the data quality coming out of intake determines the quality of everything downstream.
“Our compliance team is buried in manual audit prep”

Audit readiness in healthcare means proving, at any time, that data was handled correctly: who touched it, when, what changed, and what the source document said.
When that trail is built manually, such as through spreadsheets, email threads, and handwritten logs, it’s both unreliable and expensive to maintain.
IDP platforms generate field-level audit trails automatically. Every extraction, every validation flag, and every manual override is logged. That makes compliance something the system maintains continuously, rather than something your team scrambles to document before an inspection.
For labs operating under CAP and CLIA requirements, this is a foundational requirement for accreditation.
“We keep losing revenue to denied claims”
Claim denials are rarely random. The most common causes are often upstream intake problems that surface at the billing stage. By the time a claim is denied, the opportunity to fix the problem cheaply has already passed.
IDP vs. OCR is the right framing to consider here: basic OCR reads documents, but doesn’t validate the data or reconcile it against connected systems. IDP catches the mismatch before it reaches the payer.
That’s the difference between a prevention system and a detection system, and only one of them protects revenue.
How to Choose the Right Intelligent Document Processing Software
The difference between what IDP platforms offer matters most when your use case is specialized. Here’s what to evaluate, specifically through the lens of what Onymos is built to deliver.
Lab-Specific Document Support

Generic IDP platforms extract data from documents but aren’t trained on the specific document types labs work with daily. A platform that hasn’t been purpose-built for lab accessioning will require extensive custom configuration, and will still have gaps.
Onymos DocKnow is designed specifically for clinical and diagnostic laboratory workflows. It handles the exact document types labs process at scale, with extraction logic and validation rules built around lab-specific data relationships.
Integration With Existing Systems
IDP is only as valuable as the systems it feeds. A platform that extracts data but can’t route it cleanly into your LIMS, EHR, or billing system creates a new manual handoff which defeats the purpose.
Onymos DocKnow outputs structured, validated data via API that connects directly to LIMS, billing platforms, and analytics tools. It doesn’t replace your existing systems but it does make them work better by improving the quality of the data flowing into them.
Data Security Architecture

Where does your patient data live after the vendor processes it? Most SaaS IDP platforms store customer data on their own servers which creates HIPAA exposure, legal risk, and the single largest vector for healthcare data breaches.
Onymos’s No-Data Architecture means the platform never accesses, captures, or stores your data. All patient records, extracted data, and audit logs stay exclusively inside your own environment. Onymos is SOC 2 Type II and HIPAA compliant.
For a deeper look at what genuine healthcare security looks like in practice, review Onymos’s security benchmarks.
Stop Building What You Can Buy: Why Most IDP Teams Choose Onymos
Many labs explore building intake automation internally. Engineering teams can typically build a basic OCR extraction tool in six months.
What they can’t replicate in six months, or often at all, is SmartSync data reconciliation, upfront eligibility checks, chain-of-custody logging, HIPAA-compliant private cloud deployment, and CAP/CLIA audit readiness. Every lab that’s tried has eventually come back.
If your team runs a clinical or diagnostic laboratory and is losing revenue to intake errors, eligibility misses, or claim denials caused by bad upstream data, Onymos was built for you.
Talk to the Onymos team today.
FAQs
Is IDP the same as OCR?
No. OCR converts images of text into machine-readable characters. It reads documents but doesn’t understand them. IDP goes further by classifying documents, extracts data in context, validates it against connected systems, and routes it downstream.
How long does it take to see ROI from IDP?
Most enterprises achieve measurable ROI within 12-18 months of implementation, with some high-volume use cases showing returns within the first year. Labs with recurring claim denial problems often see impact within the first billing cycle after deployment.
Can IDP replace my LIMS or RCM system?
No, and it definitely shouldn’t try to. IDP integrates with your existing LIMS, EHR, and billing platforms to improve the quality of data flowing into them. It fills the gap that those systems leave at the intake and document processing layer.
Does IDP work with handwritten documents?
Yes. Modern IDP platforms use AI and computer vision to process handwritten forms, including handwritten test requisition forms and clinical notes, with far higher accuracy than rule-based OCR.
Is IDP only for large organizations?
No, but the ROI is highest for organizations with high document volume and complex document types. Labs processing high-volume specimens annually, financial institutions handling thousands of loan applications, and logistics companies managing high-volume customs workflows are the clearest fit. Smaller organizations benefit most when compliance requirements are strict or error costs are high.

Connect with our team to explore how Onymos solutions can maximize efficiency, minimize costs, and drive real, scalable growth.
Schedule your demoWe know healthcare data
AI in the lab. Workflow automation at scale. Digital front doors for hospitals and clinics. Healthcare and life sciences are changing fast. Are you ready? Subscribe to our blog for:
- Trends in healthcare tech
- Research and analysis
- Customer stories and more