Build or Buy Intelligent Document Processing? A 2026 Guide

Need a custom demo?
Use your own workflow and see where DocKnow can reduce manual work.
Get your demoKey Takeaways
- Buy an IDP platform like Onymos DocKnow if you’re a clinical or diagnostic lab processing high volumes of test requisition forms, insurance documents, or medical records.
- Build only if your use case is narrow, stable, and your team has dedicated ML capacity; most labs that attempt to build in-house find that validation, eligibility checks, and compliance requirements are where projects stall.
- For regulated industries, data residency is often the deciding factor. Platforms with No-Data Architecture—where PHI never touches a vendor server—significantly reduce third-party compliance risk.
- The true cost of building extends far beyond the model itself, including retraining, integration pipelines, exception handling, audit trails, and ongoing engineering maintenance.
Most engineering teams that decide to build intelligent document processing in-house start with the same assumption: we have the talent, we have the data, how hard can extraction really be?
Twelve months later, they’re back in the market looking for a vendor.
The build-or-buy intelligent document processing decision has been commoditized by tools like AWS Textract, Azure Document Intelligence, and Google Document AI.
The real question is whether your team can build and maintain everything that comes after extraction:
- Document classification and routing
- Field validation and exception handling
- Data reconciliation against existing records
- Eligibility and compliance checks
- Audit logging and chain-of-custody tracking
- Downstream system integrations (ERP, CRM, billing, or records platforms)
- Ongoing model refinement as document formats change
For any organization where a missed field or misread document triggers downstream errors such as rejected claims, failed audits, or delayed workflows, this decision has direct operational and revenue consequences.
This guide breaks down what building actually costs, what buying gets you out of the box, and how to choose the right path for your organization.
| Factor | Build In-House | Buy a Solution |
|---|---|---|
| Best For | Large engineering teams with narrow, stable document use cases | Labs and regulated enterprises processing high-volume, varied documents |
| Standout Feature | Full control over model architecture and data flows | Pre-trained models, compliance built-in, integrations on day one |
| Price | High upfront (talent + infrastructure + time); unpredictable TCO | Usage-based or modular; predictable per-document or per-module pricing |
| Pros | Maximum customization; no vendor dependency | Speed-to-value; built-in compliance; ongoing vendor R&D; support SLAs |
| Cons | Slow time-to-value; accuracy ceiling; technical debt accumulates fast | Less control over underlying models; pricing requires custom quote |
| No-Data Architecture | Your responsibility | Available natively in platforms like Onymos |
| HIPAA / SOC 2 | Must be built and maintained internally | Included in leading solutions |
| Integrations | Custom-built and maintained | Pre-built connectors to LIMS, EHRs, billing platforms |
Building IDP In-House: What It Really Takes
Building an IDP system might sound like an extraction problem but it isn’t.
Extraction, i.e., reading text off a PDF or scanned form, has been a solved problem since the rise of modern Optical Character Recognition and, more recently, Vision Language Models and Generative AI.
What most internal build plans underestimate is the scope of what follows extraction: classification, cross-source validation, data reconciliation, upfront eligibility checks, compliance tracking, exception routing, audit logging, and deep integration with existing systems.
Getting data out of a document is step three of a nine-step process. Building in-house means owning all nine.
Before greenlighting a build, map your full document workflow end-to-end—from intake through system-of-record update. Most teams discover that extraction is less than 20% of the actual problem.
What Your Team Needs to Build IDP
- ML and data science talent: You need engineers who can train, fine-tune, and maintain models on your specific document types, not just developers who can call an API. For documents with extreme variability across sources, formats, or issuing entities, this requires deep domain expertise.
- Infrastructure: A scalable cloud or on-prem environment to handle variable document volumes, latency requirements, and the storage demands of structured and unstructured documents, all within your data governance boundaries.
- Compliance expertise: HIPAA compliance, SOC 2 certification, CAP and CLIA audit readiness, and chain-of-custody logging don’t come with your extraction model. In-house builds put the governance burden entirely on your team, with no vendor backstop.
- Continuous retraining: Models degrade. Document formats change across ordering providers, payers, and regulatory bodies. Ongoing model refinement and model lifecycle management are non-negotiable if you want accuracy above 90-95% at scale.
- Integration pipelines: Your IDP system needs to connect to your existing LIMS, RCM platform, EHR, and billing systems. These REST APIs don’t build themselves, and they break every time a downstream system updates.
The Hidden Costs of Building IDP In-House
- Talent cost: A single senior ML engineer costs $150,000–$220,000 annually in the US. Add data scientists, DevOps, and QA for a realistic production team, and you’re looking at $500,000+ per year of infrastructure, before you’ve processed a single document in production.
- Technical debt: Custom builds accumulate debt fast, especially as AI technologies evolve and document formats change. The accuracy-harnessing work that felt done at launch becomes a quarterly firefighting exercise within 18 months.
- Opportunity cost: Every sprint your engineering team spends on IDP pipelines is a sprint not spent on your core product or lab operations. This is the cost that never appears on a budget line but is often the most damaging.
- Time-to-value gap: Most in-house IDP projects take 6 to 18 months to reach production maturity. A bought solution can be operational in days. For organizations losing revenue on processing errors today, that gap is measured in real dollars.
When Building Makes Sense
- Single, stable use case: If you process one document type in one workflow that is unlikely to change, and you have a dedicated platform team to own it, a build can be more cost-effective long-term. This describes very few labs.
- Proprietary data requirements: If regulatory constraints mean your documents cannot touch any external system under any circumstances, building in-house may be your only option.
Platforms with No-Data Architecture, where processing happens entirely within your own cloud, have largely eliminated this objection for HIPAA-regulated teams.
- Large, dedicated engineering capacity: If your organization has hundreds of engineers and can commit long-term headcount to an IDP platform, and that’s genuinely a core competency you want to own, building is a logical choice.
Where Building Falls Short
- Extraction ≠ automation: The majority of in-house builds focus on Optical Character Recognition and data extraction. Validation systems, reconciliation against insurance records, upfront eligibility checks, and compliance checks are typically left to manual processes, defeating the point of automation entirely.
- Accuracy ceiling: Achieving 90-95% accuracy on clean documents is feasible in-house. Pushing above that threshold on real-world, high-variability documents requires years of iteration, explainable AI tooling, and specialized R&D most teams don’t have the capacity for.
- Workflow failure at scale: Internal builds often succeed in demos and controlled pilots. They break down at production scale when exception handling, edge cases, and system integrations create workflow bottlenecks that the original build didn’t anticipate.
Buying an IDP Solution: What You Get Out of the Box
Buying an IDP platform means plugging into years of R&D, pre-trained models, compliance infrastructure, and integration libraries that your team would otherwise spend 12-18 months building from scratch.
The most important distinction: leading IDP platforms aren’t just extraction tools but also orchestrate the complete document lifecycle as a fully connected workflow.
That’s the gap between a raw data feed and actual document automation.
What a Bought IDP Solution Provides
- Pre-trained models: Vendors have trained on millions of documents across diverse formats. For healthcare-specific platforms, that includes test requisition forms, insurance cards, remittance advice, EOBs, and patient records. You inherit that training data from day one.
- Compliance built in: Leading platforms include HIPAA compliance, SOC 2 certification, and data-residency controls as product features. For labs operating under CLIA and CAP audit requirements, this alone can justify the buy decision. For enterprise teams managing documents across multiple business lines or external partners, pre-built integrations reduce the connector maintenance burden that typically falls on internal engineering.
- Integrations: Pre-built connectors to existing LIMs, EHRs, RCM platforms, Salesforce, AWS, Azure, and Google Cloud Platform are standard in mature IDP solutions. No custom connector maintenance, no integration pipelines to rebuild when downstream systems update.
- Ongoing updates: Model improvements, new document type support, Generative AI capability expansions, and security patches are handled by the vendor. Your team inherits every improvement without additional development cycles.
- Support and SLAs: Dedicated support teams and contractual service-level agreements don’t usually exist for in-house builds. When a model breaks on a Monday morning during peak accessioning volume, a vendor SLA is the difference between a one-hour fix and a four-day incident.
When Buying Clearly Wins
- Broad or evolving use cases: If your document types, volumes, or lab workflows are likely to change (due to new payers, new requisition form formats, expanded test menus), a vendor platform absorbs that complexity. You configure; they maintain.
- Regulated industries: Healthcare, finance, legal — anywhere compliance is non-negotiable and governance gaps can result in HIPAA violations, failed audits, or lost reimbursement. The Total Cost of Ownership calculus here almost always favors buying.
- Speed-to-value priority: If you’re losing money on billing errors and claim denials today, time-to-production measured in weeks rather than months is a basic business requirement.
- Lean engineering teams: Most teams running document-heavy workflows operate leaner than the IDP problem demands. Buying eliminates an entire category of maintenance work (think: model lifecycle management, integration pipeline upkeep, compliance documentation) that your team was never resourced to own.
What to Watch Out For When Buying
- Data residency: This is non-negotiable in any regulated context. Confirm that your data never leaves your infrastructure. A platform like Onymos DocKnow with true No-Data Architecture eliminates this risk category entirely, particularly relevant if you operate in healthcare, finance, or legal.
- Vendor lock-in: Look for platforms built on open standards with portable configurations. The more a platform requires you to adapt your workflows to fit its architecture, rather than the reverse, the more expensive switching becomes.
- Customization limits: Confirm the platform allows you to train on your own document data and configure validation systems to your specific workflows. Generic AI tools trained on general-purpose data will underperform on the specific document variability your enterprise, company, or lab sees daily.
Onymos: A Buy Solution for Clinical and Diagnostic Labs That Can’t Afford Intake Errors

Onymos DocKnow is the recommended buy solution for clinical and diagnostic laboratories, and the only IDP platform purpose-built specifically for laboratory intake, test requisition processing, and the full accessioning-to-reimbursement workflow.
Where general-purpose IDP platforms offer road applicability across industries, DocKnow is built around the exact document types, compliance requirements, and downstream systems that diagnostic labs operate with every day.
Onymos Key Features
DocKnow’s value sits in three capabilities that directly address where in-house builds and general IDP tools fall short in clinical laboratory settings.
- No-Data Architecture

DocKnow processes all document data entirely within the customer’s own cloud environment or on-premises. No patient data, PHI, or PII flows through Onymos servers at any point. This is how Onymos built its software from the ground up, not a privacy add-on.
Onymos has earned the 2024 Fortress Cybersecurity Award for this approach and maintains SOC 2 and HIPAA compliance as baseline product requirements.
Most SaaS platforms offer “private cloud” or “on-prem” options as paid upgrades. With Onymos, No-Data Architecture is the default.
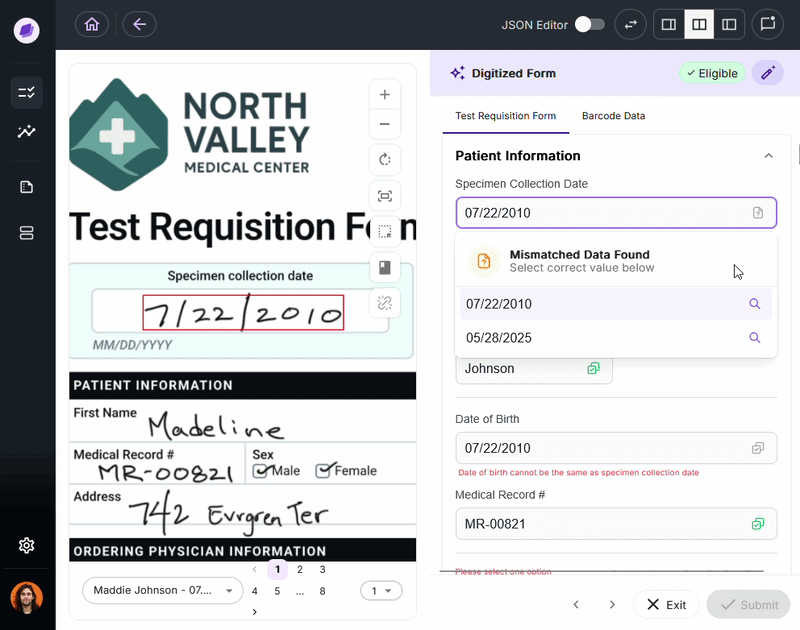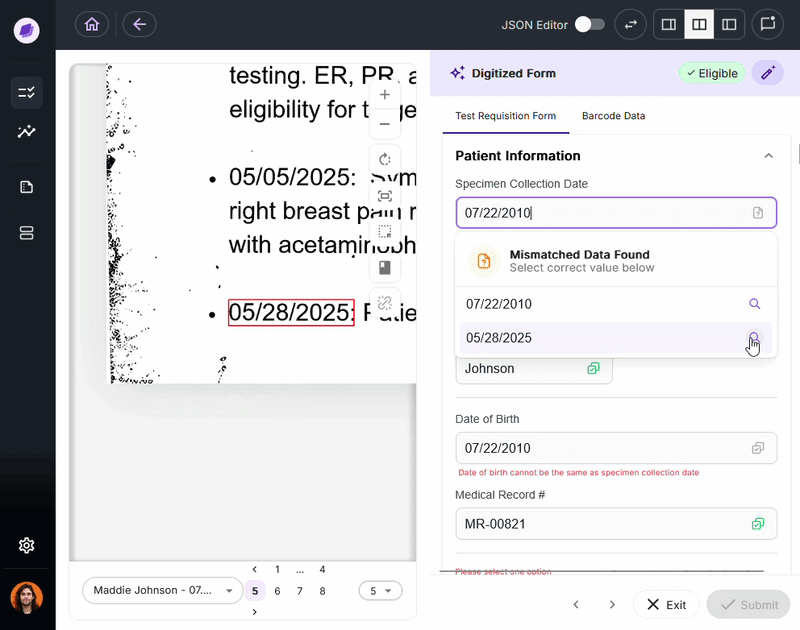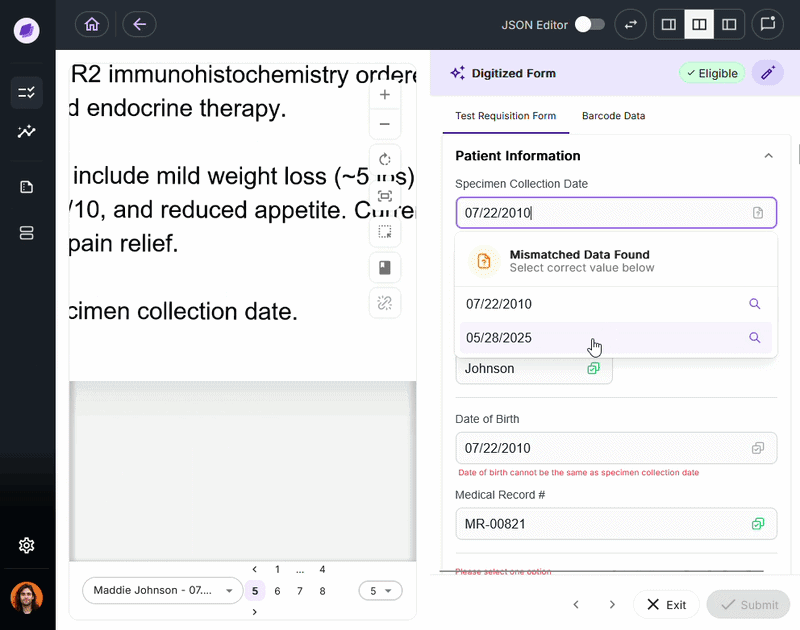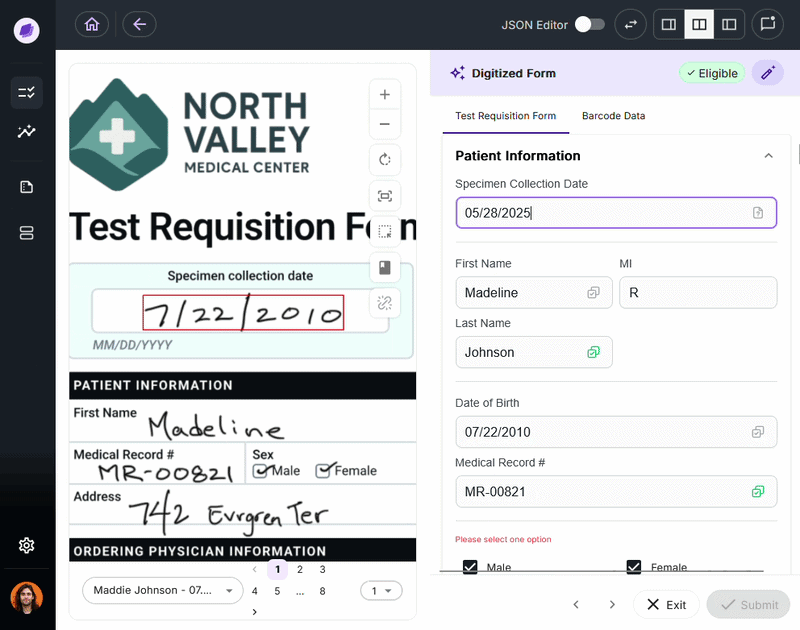
Nucleus is the underlying AI system powering DocKnow’s intelligence layer. Unlike generic large language models trained on general-purpose data, Nucleus is built around healthcare and laboratory document processing:
- Reading test requisition forms
- Cross-referencing patient records
- Running eligibility checks
- Tracking every document interaction for compliance
- Full-Stack, Modular Architecture

DocKnow automates the complete laboratory intake workflow: reading test requisition forms, extracting patient and insurance data, running upfront eligibility checks, flagging mismatches, reconciling data across sources, and connecting directly to existing LIMS and RCM systems.
It’s an end-to-end process platform where every field is captured, validated, and cleaned before it reaches your system of record.
Onymos Pricing
Onymos offers modular architecture which means labs only pay for the capabilities they need.
There’s no need to purchase a platform designed for industries where their use case doesn’t fit.
There is no flat SaaS subscription; pricing scales with your lab’s throughput.
Where Onymos Shines
- Healthcare and life sciences workflows: Onymos is trained on thousands of healthcare documents and includes built-in ICD/CPT taxonomy integrations; purpose-built for lab accessioning, prescription forms, and clinical intake.
- Security-sensitive enterprises: The No-Data architecture is rare in the IDP market. For labs that have had a vendor security conversation derailed by data residency concerns, Onymos typically ends that conversation before it starts.
- Revenue cycle teams losing money on denials: DocKnow’s upfront eligibility checks catch insurance coverage problems before a test is even run. For labs where eligibility-related denials represent a material percentage of revenue loss, this single capability can generate positive ROI within the first billing cycle.
Where Onymos Falls Short
- General-purpose enterprise use: DocKnow is purpose-built for clinical and diagnostic laboratories. Teams in unrelated verticals will find fewer pre-built integrations and document models relevant to their workflows.
- Pricing transparency: Usage-based, modular pricing is flexible and fair for high-volume labs, but harder to forecast upfront for teams accustomed to flat SaaS subscriptions.
Onymos Customer Reviews
Onymos counts CVS, Albertsons, and Guardant Health among its known customers.
Stephen Fairclough, the former VP of Informatics at Personalis, also speaks highly of Onymos’s results on LinkedIn. He praised, “The Onymos team know their stuff. Beyond the accuracy of DocKnow, the traceability of their solution differentiates them from other players in the space.”

Another Onymos user also says, “Onymos is a great partner and enabled us to quickly get our Proof of Concept completed. They were very responsive and collaborative, and we had a successful Proof Of Concept deployment.”
→ Read more: Our customer success stories
Who Onymos is Best For
- Healthcare labs and diagnostic companie managing high-volume requisition forms, patient intake, and specimen-level data that feeds directly into billing and reimbursement workflows
- Regulated enterprises needing data sovereignty especially any team that cannot send PHI or PII to third-party servers under HIPAA, and needs No-Data Architecture as a baseline, not a premium add-on
- Engineering teams that want speed without sacrificing control as custom LLM training gives the control of a build with the speed of a buy
How to Decide: Build or Buy IDP?
Most build-or-buy frameworks give you a generic pros and cons list. This one gives you the four questions that actually determine the right answer for an enterprise, a laboratory or healthcare organization.
What Is Your Time-to-Revenue Requirement?
If your organization is currently losing revenue due to document processing errors, rejected transactions, or manual data entry backlogs, how long can you absorb that loss while an in-house build matures?
In-house IDP solutions typically take 6-18 months to reach production stability. Bought platforms can be operational in weeks.
If you started building today, what would your cumulative revenue loss from processing errors and operational delays be at the 12-month mark? That number is the true cost of the build option.
Do You Have the Compliance Infrastructure to Own This?
HIPAA compliance, SOC 2 certification, CLIA audit readiness, and chain-of-custody logging are not features you add to an IDP build. They are governance programs that require dedicated expertise, ongoing documentation, and annual audits.
When you buy a platform with compliance built in, that burden transfers (in part) to the vendor.
When you build, you own it entirely.
For most enterprises, companies, and labs, this is a significant and often underestimated operational load.
How Stable Is Your Document Scope?
IDP builds work best when the document types, formats, and workflows they handle are narrow and unlikely to change. In clinical laboratory environments, enterprise operations, and any organization processing documents from multiple external sources, this stability rarely exists.
Every document variability event in a built system is an engineering sprint. In a bought system, it’s typically a configuration update or vendor-handled model refinement.
If your document scope is likely to expand, the ongoing model lifecycle management burden of a built system scales with that expansion.
What Is Your Total Cost of Ownership Over 3 Years?
Year one of a build can look cheaper than a vendor contract. Years two and three rarely do.
You need to factor in:
- Ongoing ML engineer salaries
- Infrastructure costs
- Retraining cycles
- Integration maintenance every time a downstream system updates
- Compliance documentation overhead
- The opportunity cost of engineering capacity diverted from your core product
Most organizations that run a realistic 3-year Total Cost of Ownership analysis find that a purpose-built IDP platform is equal to or less expensive than the fully-loaded cost of maintaining a build.
Read more on our developer resources: Onymos API Docs | Frameworks | Quickstart Guides | App Development Platform
Stop Building What You Can Buy: Why Most IDP Teams Choose Onymos
If your organization processes high volumes of structured documents across complex workflows and needs speed, compliance, and integration coverage without the engineering overhead of a build, a purpose-built IDP platform like DocKnow is the faster path to the same outcome.
The labs that come to Onymos after a failed build share a common story: they solved extraction, then discovered that the real problem was everything else.
For everyone in the clinical and diagnostic lab space, the build path is a longer, more expensive route to the same destination.
Ready to see what the intake layer of your lab could look like?
Contact Onymos or try DocKnow with your own documents!
FAQs
Is intelligent document processing the same as OCR?
No. Optical Character Recognition reads text from images and scanned documents. Intelligent document processing uses natural language processing, image recognition, and AI technologies to understand what that text means, validate it against other data sources, run compliance checks, and route it into downstream systems.
How long does it take to go live with a bought IDP solution?
For platforms like DocKnow, most labs reach production within weeks, not months. The specific timeline depends on integration complexity with your existing LIMS and RCM systems. This compares to 6-18 months for most in-house builds to reach equivalent production stability.
How does No-Data Architecture work in practice?
No-Data Architecture means the IDP platform (such as Onymos DocKnow) is deployed within your own cloud infrastructure. Document data is processed on your servers, by your compute. Onymos supplies the software and AI models; your data never leaves your environment.

Connect with our team to explore how Onymos solutions can maximize efficiency, minimize costs, and drive real, scalable growth.
Schedule your demoWe know healthcare data
AI in the lab. Workflow automation at scale. Digital front doors for hospitals and clinics. Healthcare and life sciences are changing fast. Are you ready? Subscribe to our blog for:
- Trends in healthcare tech
- Research and analysis
- Customer stories and more